音声や動画の文字起こしは、ビジネスや学術研究、コンテンツ制作など様々な場面で重要です。注目したいのが、Google ColaboratoryとOpenAIのWhisperを組み合わせた無料で高精度な文字起こし方法を試してみます。
Google Colaboratoryの設定
Google Colaboratory(通称Colab)にアクセスし、新しいノートブックを作成します。
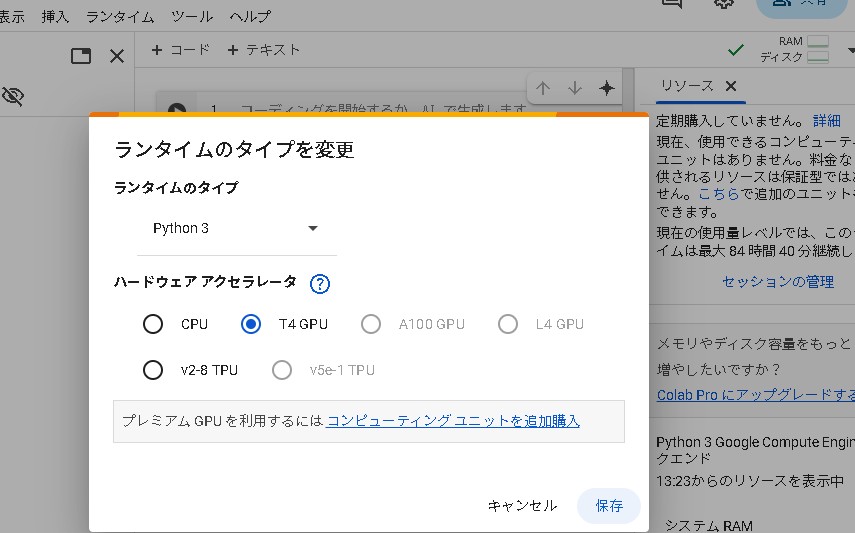
ランタイムのタイプをGPUに変更します。これにより処理速度が向上します。
必要なライブラリのインストール
Colabのセルに以下のコードを入力し実行します。
!pip install git+https://github.com/openai/whisper.git
import whisper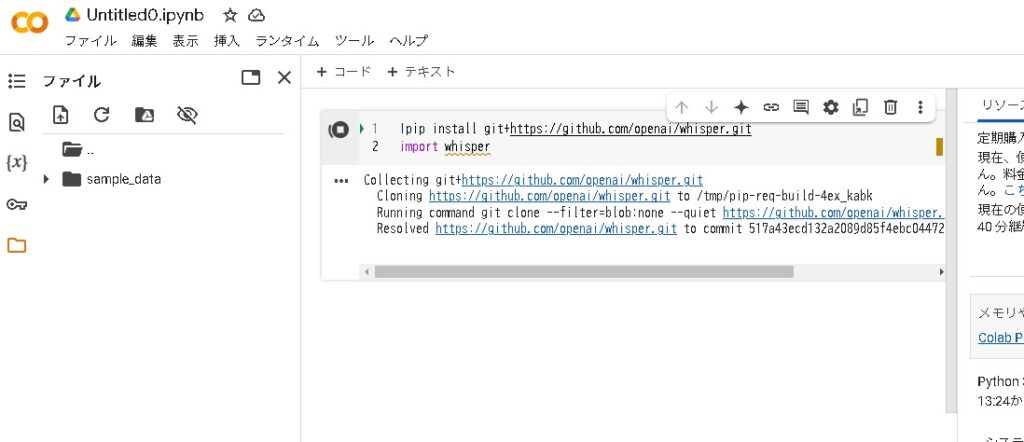
文字起こし実践(音声ファイルのアップロード)
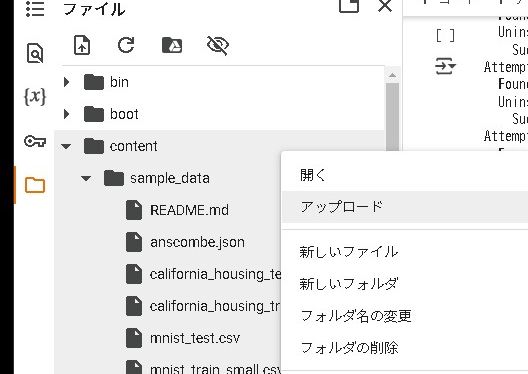
- Colabの左側のメニューから「ファイル」タブを開きます。
- 「アップロード」をクリックし、文字起こしする音声ファイルを選択します。
Whisperモデルのロード
以下のコードでWhisperの大規模モデルをロードします。
model = whisper.load_model('large')もし処理が重たかったり時間がかかる場合は、他のモデルを検討しましょう。
‘large’モデル以外にも複数のモデルがある
Whisperには’large’モデル以外にも複数のモデルが用意されています。主なモデルは以下の通りです。
- tiny: 最小のモデルで、処理速度は最も速いですが精度は低めです.
- base: tinyより大きく、精度も向上しますが、誤字が見られることがあります.
- small: baseより大きく、文字起こし精度が更に向上します。これがデフォルトモデルとなっています.
- medium: smallより大きく、かなり正確な文字起こしが可能で、句読点も適切に打つことができます.
- large-v2: 2023年に追加された改良版のlargeモデルです.
- large-v3: 最新版で、日本語の単語誤り率がさらに改善されています.
- turbo: 2024年10月に追加された新しいモデルで、largeモデルに近い精度を持ちながら、処理速度が大幅に向上しています.
各モデルは多言語対応版と英語限定版があり、必要なGPUメモリや処理速度が異なります。
モデルの選択は、求める精度と利用可能なコンピューティングリソースのバランスを考慮して行うことがポイントです。
文字起こしの実行
アップロードした音声ファイルの文字起こしを行います。
result = model.transcribe('your_audio_file.mp3')
print(result['text'])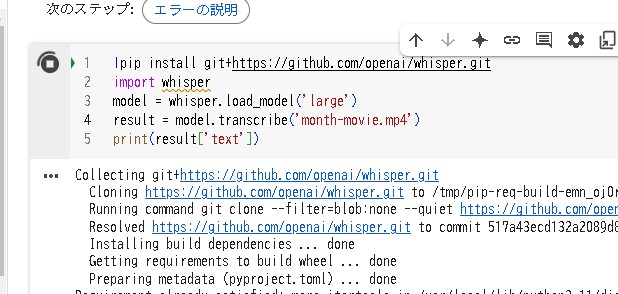
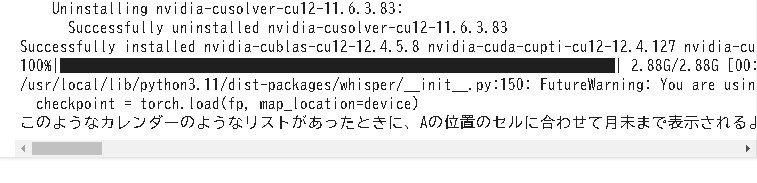
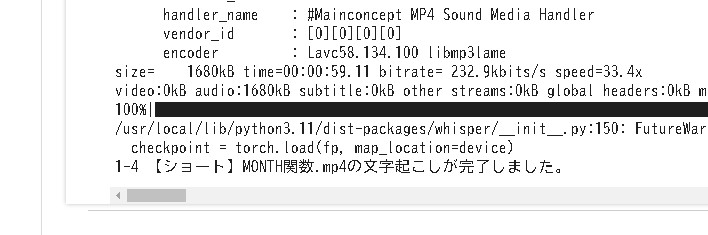
実行した結果がプリントで出力されました。
テキストを貼り付けた状態です。
なかなか正確な感じで日本語化されていることが分かります。漢字やカタカナもかなり精度が高いように見えます。
応用テクニック(言語指定)
日本語の文字起こしを行う場合、以下のように言語を指定すると精度が向上します。
result = model.transcribe('your_audio_file.mp3', language='ja')自動翻訳機能の活用
Whisperには自動翻訳機能も搭載されています。
以下のコードで英語に翻訳できます。
result = model.transcribe('your_audio_file.mp3', task='translate')
トラブルシューティング
- メモリ不足エラー: モデルサイズを’medium’や’small’に変更してみてください。
- 音声ファイルが認識されない: ファイル名やパスが正しいか確認しましょう。
まとめ
あとは、設定次第でGoogleドライブに自動保存するようなこともできます。続きはまた。
Google ColaboratoryとWhisperを使用することで、無料で高精度な文字起こしが可能になります。この方法は多言語対応できる点もよいです。
ご参考ください。