目次
セルの中から、特定の規則に従った文字を抽出したい場合は「REGEXREPLACE関数」が使えます。
REGEXREPLACE関数とは?
REGEXREPLACEは、Google Sheetsで文字列中のテキストを正規表現パターンに基づいて置換するために使用される関数です。
次のような構文を持ちます:
=REGEXREPLACE(テキスト、正規表現、置換)テキスト(text)は変更したい文字列です- 正規表現(
regular_expression)は置換するテキストを定義するパターンです 置換(replacement)はtext内に一致したテキストを置き換えるテキストです
例:
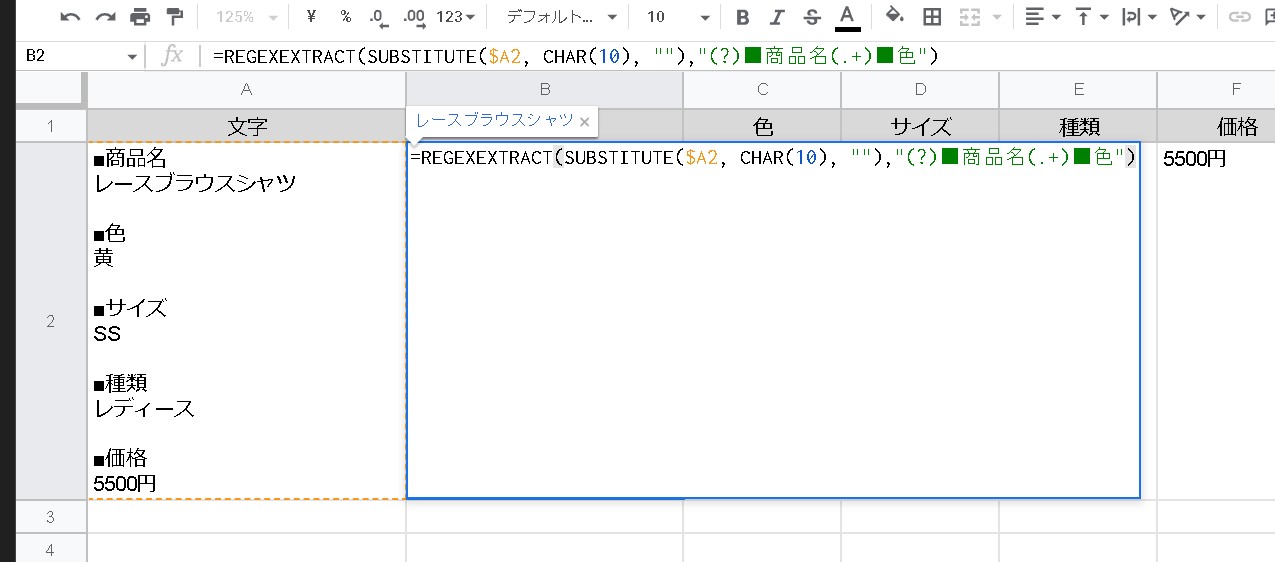
=REGEXREPLACE("Hello World!","Hello","Goodbye")この時、結果は「Goodbye World!」を返します。
REGEXREPLACE関数の応用例
上記の場合だと、文字をただ置換しただけですので、SUBSTITUTE関数と同じような扱いになります。
REGEXREPLACE関数のメリットは「正規表現」が使えるところですので、少し応用してみます。
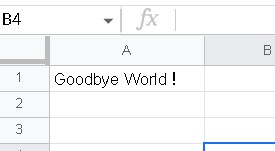
例えば、このようなデータがあった場合に、他の列にそれぞれの内容を抽出して表示させる場合を考えてみます。

この場合は、「■商品名」が見つかったら次の行である「レースブラウスシャツ」を抽出、「■色」が見つかったら「黄」・・・といったように正規表現で見つけていきます。
Google では RE2 構文のみをサポートしている?
なお、Google では RE2 構文のみをサポートしているようです。

正規表現の例 - Google Workspace 管理者 ヘルプ
次の例は、基本的な正規表現の使い方と構造を示しています。それぞれの例には、検索対象の文字列の種類、その文字列と一致する正規表現、特殊文字の使い方についての説明が含まれています。 完全一致のフレーズを検索する リスト内の単語またはフレーズを検...
support.google.com

Syntax
RE2 is a fast, safe, thread-friendly alternative to backtracking regular expression engines like those used in PCRE, Per...
github.com
RE2構文の正規表現(例):
| 例 | 一文字式の種類 |
|---|---|
| . | 改行を含む任意の文字 (s=true) |
| //a/@href | 0回以上の繰り返し |
| + | 1回以上の繰り返し |
| ? | 0回または1回の出現 |
| {n,m} | n回以上、m回以下の繰り返し |
| [xyz] | 文字クラス |
| [^xyz] | 否定文字クラス |
| \d | Perl 文字クラス |
| \D | 否定された Perl 文字クラス |
| [[:alpha:]] | ASCII 文字クラス |
| [[:^alpha:]] | 否定された ASCII 文字クラス |
| ^● | 先頭に●のある文字列 |
| ●$ | 末尾に●のある文字列 |
| [●] | ●に一致する文字列 |
正規表現で改行されたデータから文字を抽出する
例えば、下のような表から、正規表現でそれぞれの項目を抽出してみます。
[rml_read_more]
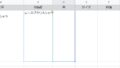
=REGEXEXTRACT(SUBSTITUTE($A2, CHAR(10), ""),"(?)■商品名(.+)■色")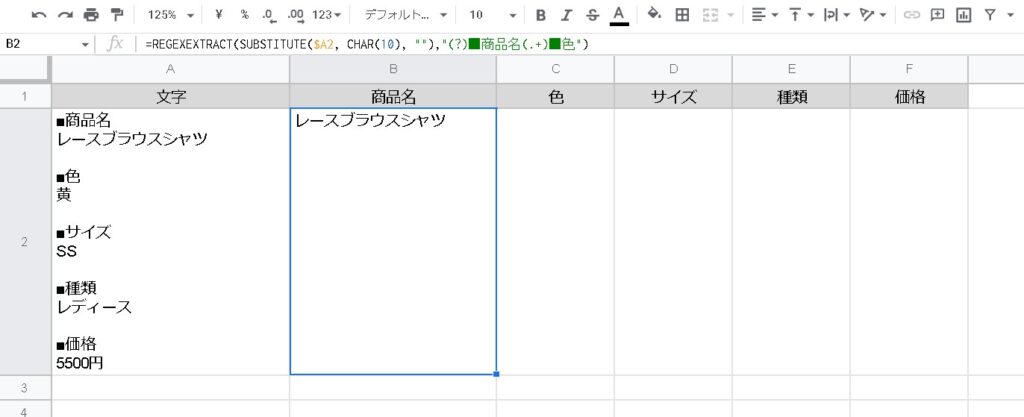
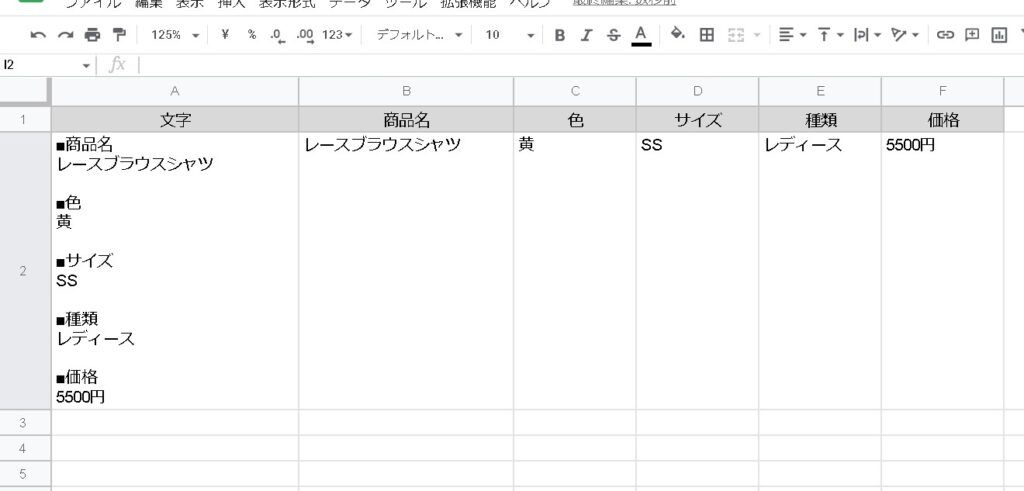
=REGEXEXTRACT(SUBSTITUTE($A2, CHAR(10), ""),"(?)■色(.+)■サイズ")=REGEXEXTRACT(SUBSTITUTE($A2, CHAR(10), ""),"(?)■サイズ(.+)■種類")=REGEXEXTRACT(SUBSTITUTE($A2, CHAR(10), ""),"(?)■種類(.+)■価格")=REGEXEXTRACT(SUBSTITUTE($A2, CHAR(10), ""),"■価格(.+)")これで、■色~■サイズ、■サイズ~■種類、■種類~■価格、■価格~、のそれぞれの文字が抽出できました。
まとめ
このように、EGEXREPLACE関数を使うと、正規表現を使って、様々な文字列を抽出したり置換することができます。
使い方次第でかなり便利に使えますので、ぜひ覚えておくと便利です。