REGEXEXTRACT 関数
Google スプレッドシートの REGEXEXTRACT 関数は、指定されたテキストから正規表現に一致する部分を抽出するために使用されます。
この関数は、テキスト内で正規表現パターンに一致する最初のインスタンスを見つけ出し、その一致したテキストを返します。REGEXEXTRACT 関数は、データの解析や特定のパターンに基づく情報の抽出に非常に便利です。
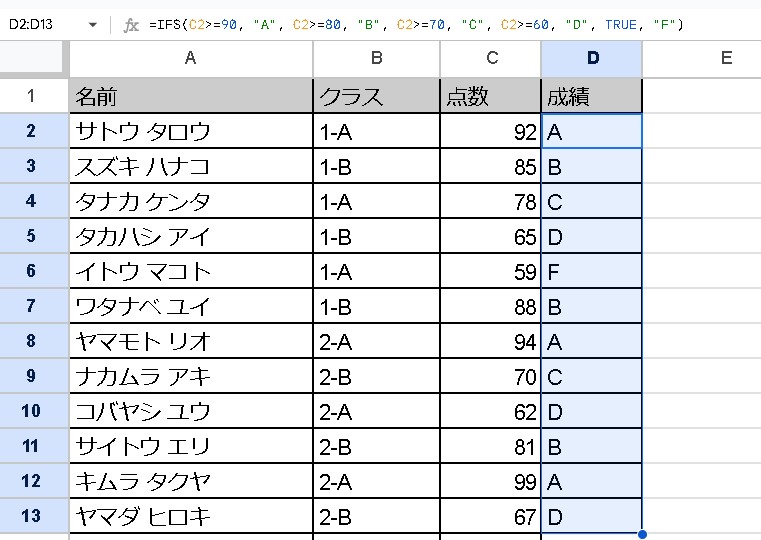
REGEXEXTRACT(text, regular_expression)textは、検索対象のテキストです。regular_expressionは、抽出するテキスト部分に一致させるための正規表現パターンです。
正規表現の基本的な使用例
- 単純なワードの抽出:
- 例:
"Hello, world!"から"Hello"を抽出する。 - 式:
=REGEXEXTRACT("Hello, world!", "Hello") - 結果:
"Hello"
- 例:
- メールアドレスからドメイン名を抽出:
- 例:
"example@gmail.com"から"gmail.com"を抽出する。 - 式:
=REGEXEXTRACT("example@gmail.com", "@(.+)") - 結果:
"gmail.com"
- 例:
- 数字の抽出:
- 例:
"Total: 1234"から数字の"1234"を抽出する。 - 式:
=REGEXEXTRACT("Total: 1234", "\d+") - 結果:
"1234"
- 例:
正規表現の基本的な構成要素
- リテラル(Literal)文字: 通常の文字(例えば ‘a’ や ‘1’)は、それ自体がパターンの一部として認識されます。
- ドット(.): 任意の1文字にマッチします(改行文字を除く)。
- キャラクタークラス: 特定の文字群の中から1文字にマッチさせたい場合に使用します。例えば、
[abc]は ‘a’, ‘b’, ‘c’ のいずれか1文字にマッチします。 - 否定キャラクタークラス: 特定の文字を除外してマッチさせたい場合に使用します。例えば、
[^abc]は ‘a’, ‘b’, ‘c’ 以外の任意の1文字にマッチします。 - 繰り返し:
*(アスタリスク): 直前の要素の0回以上の繰り返しにマッチ。+(プラス): 直前の要素の1回以上の繰り返しにマッチ。?(クエスチョン): 直前の要素が0回または1回出現する場合にマッチ。{n}: 直前の要素がn回繰り返される場合にマッチ。{n,}: 直前の要素がn回以上繰り返される場合にマッチ。{n,m}: 直前の要素がn回からm回の間に繰り返される場合にマッチ。
- 位置指定子:
^: 文字列の開始位置にマッチ。$: 文字列の終了位置にマッチ。\b: 単語の境界にマッチ(例:\bword\bは、独立した単語 “word” にマッチします)。\B: 単語の境界でない位置にマッチ。
- エスケープ文字: 特別な意味を持つ文字(例えば
*や.など)をリテラルとして扱いたい場合にバックスラッシュ (\) を使用します。
ハッシュタグを抽出する
スプレッドシートの REGEXEXTRACT 関数を使ってハッシュタグを抽出することはできますが、直接ハッシュタグを削除することはできません。REGEXEXTRACT 関数は、指定した正規表現に一致するテキストの部分を抽出するためのものです。そのため、ハッシュタグを削除する代わりに、ハッシュタグを含まないテキストを抽出したい場合は、別のアプローチを取る必要があります。
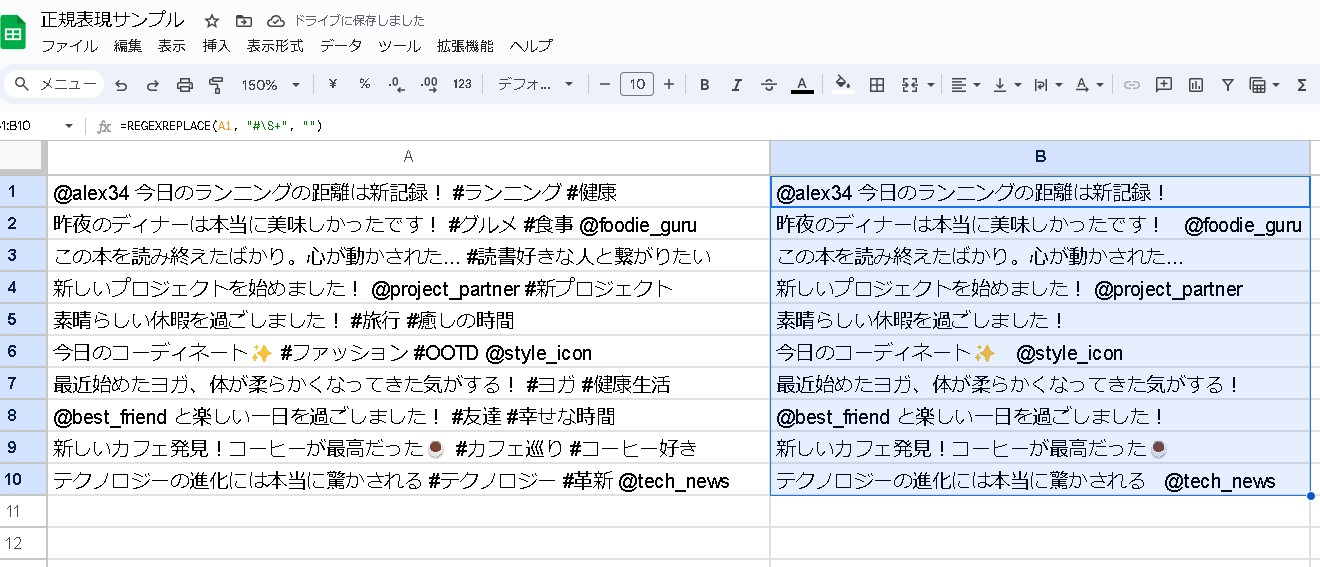
ハッシュタグを除外して残りのテキストを取得したい場合は、REGEXREPLACE 関数を使用することで、指定した正規表現に一致するテキストを置換または削除することができます。ハッシュタグを削除するには、ハッシュタグにマッチする正規表現(#\S+)を使用し、それを空文字列に置換します。
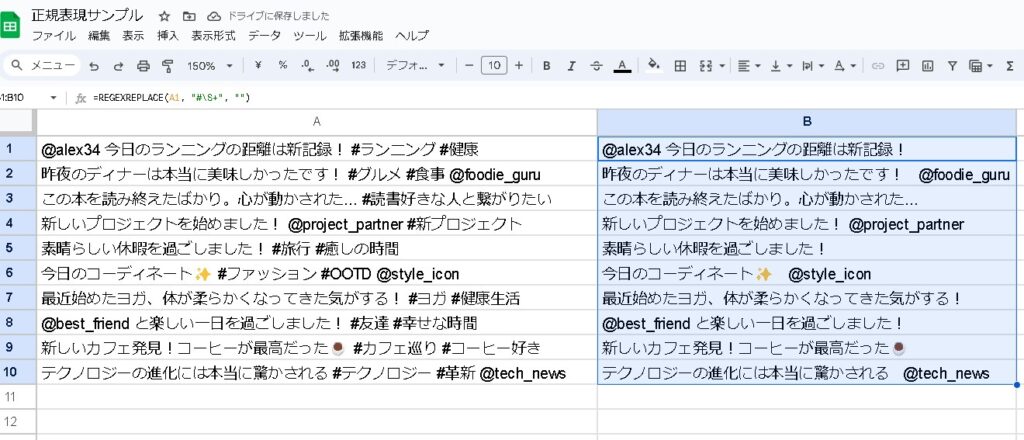
以下の例では、REGEXREPLACE を使用してセル内のハッシュタグを削除します。
=REGEXREPLACE(A1, "#\S+", "")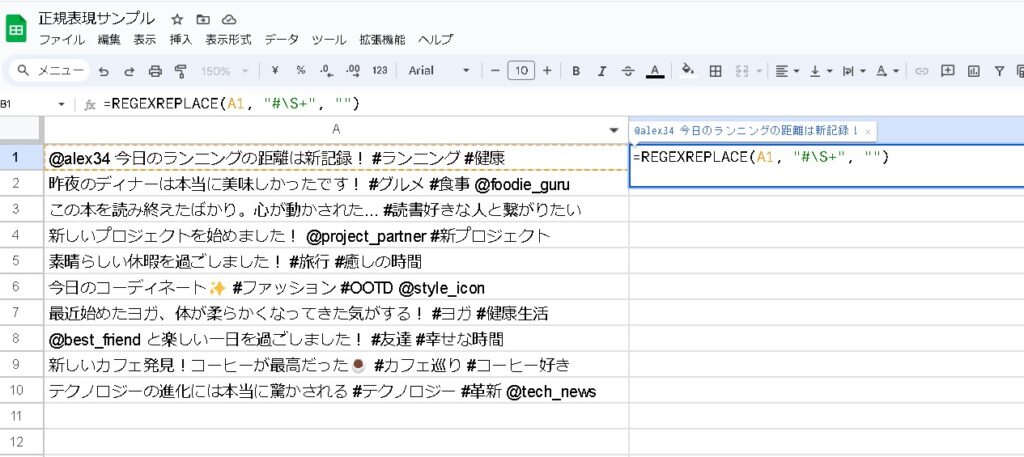
この式は、セル A1 内のテキストから、# 記号に続く任意の非空白文字列(ハッシュタグ)を削除します。ここで、#\S+ は # に続く1文字以上の非空白文字にマッチする正規表現です。
注意点
- REGEXEXTRACT 関数は、一致するテキストが見つかった場合にのみ値を返します。一致するものがない場合、エラーが発生します。
- 使用する正規表現は、抽出したい具体的なテキストパターンに基づいて適切に設計する必要があります。
- 正規表現には特定のルールと構文があり、パターンマッチングの精度を高めるためには、これらのルールを理解しておくことが重要です。
まとめ
この方法を使用すると、指定したセルからハッシュタグを効率的に削除し、ハッシュタグ以外のテキストのみを残すことができます。正規表現は非常に強力ですが、複雑になりがちなので、使い始める際は簡単なパターンから始め、徐々に複雑なパターンへと進んでいくことをお勧めします。
つづきは、また。