目次
REGEXREPLACE関数とは
REGEXREPLACE関数は、テキスト文字列内のテキストを正規表現を使用して検索し、置換する関数です。
=REGEXREPLACE(テキスト, 正規表現, 置換)テキスト – 一部を置換する対象のテキスト
正規表現 – この正規表現に一致するすべてのインスタンスが置き換えられる
置換 – 元のテキストに挿入されるテキスト
一般的に使用される正規表現のパターン
一般的に使用される正規表現のパターンを表にまとめます。
| 正規表現のパターン | 意味 | 例 |
|---|---|---|
. | 任意の単一文字に一致する(改行文字を除く)。 | a.c は “abc”, “adc”, “a&c” に一致しますが、”ac” には一致しません。 |
* | 直前の文字の0回以上の繰り返しに一致する。 | ab*c は “ac”, “abc”, “abbc”, “abbbc” に一致します。 |
+ | 直前の文字の1回以上の繰り返しに一致する。 | ab+c は “abc”, “abbc”, “abbbc” に一致しますが、”ac” には一致しません。 |
? | 直前の文字の0回または1回の出現に一致する。 | ab?c は “ac”, “abc” に一致しますが、”abbc” には一致しません。 |
^ | 文字列の開始に一致する。 | ^abc は “abc” で始まる任意の文字列に一致します。 |
$ | 文字列の終了に一致する。 | abc$ は “abc” で終わる任意の文字列に一致します。 |
[] | 括弧内の任意の単一文字に一致する。 | [abc] は “a”, “b”, “c” のいずれか一文字に一致します。 |
[^] | 括弧内にない任意の単一文字に一致する(否定)。 | [^abc] は “a”, “b”, “c” を除く任意の一文字に一致します。 |
\( \) | 括弧内の表現に一致し、キャプチャ(後で参照可能)する。 | (abc)+ は “abc”, “abcabc”, “abcabcabc” に一致します。 |
| | 左右のいずれかの表現に一致する(論理和)。 | abc|def は “abc” または “def” に一致します。 |
{n} | 直前の文字のn回の繰り返しに一致する。 | ab{2}c は “abbc” に一致しますが、”abc”, “abbbc” には一致しません。 |
{n,} | 直前の文字のn回以上の繰り返しに一致する。 | ab{2,}c は “abbc”, “abbbc”, “abbbbc” に一致しますが、”abc” には一致しません。 |
{n,m} | 直前の文字のn回以上、m回以下の繰り返しに一致する。 | ab{1,3}c は “abc”, “abbc”, “abbbc” に一致しますが、”abbbbc” には一致しません。 |
この表は正規表現を使用する際の基本的な方法です。
()の中のひらがなのみを削除する(前回の続き)
例えば、このようなテキストがあった場合に、()の中のひらがなのみを削除できます。
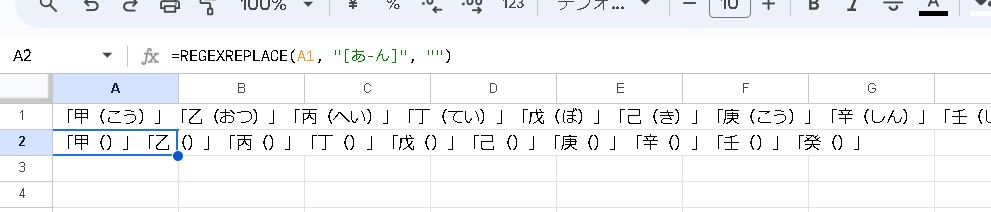
「甲(こう)」「乙(おつ)」「丙(へい)」「丁(てい)」「戊(ぼ)」「己(き)」「庚(こう)」「辛(しん)」「壬(じん)」「癸(き)」
=REGEXREPLACE(A1, "[あ-ん]", "")ひらがなが全て削除されて表示されます。
テキストから丸括弧(( や ))または全角の丸括弧(( や ))で囲まれたすべての部分を削除する
丸括弧(( や ))または全角の丸括弧(( や ))で囲まれたすべての部分を削除してみます。
「甲(こう)」「乙(おつ)」「丙(へい)」「丁(てい)」「戊(ぼ)」「己(き)」「庚(こう)」「辛(しん)」「壬(じん)」「癸(き)」下記の式は、A1セル内のテキストから、丸括弧(( や ))または全角の丸括弧(( や ))で囲まれたすべての部分を削除します。正規表現のパターン [\((][^\))]*[\))] は以下のように機能します:
=REGEXREPLACE(A1,"[\((][^\))]*[\))]","")今回使用した正規表現のパターンまとめです。
| 正規表現のパターン | 意味 | 例 |
|---|---|---|
[\((] | 開始の括弧を見つける。半角の ( または全角の ( のいずれかに一致する。 | 文字列「これは(テスト)です」や「これは(テスト)です」の中の「(` または「(」に一致します。 |
[^\))]* | 閉じ括弧が現れるまでの任意の文字の0回以上の繰り返しに一致する。^ は否定の意味を持ち、) または ) 以外の任意の文字に一致する。 | 「(テスト)」や「(テスト)」の中の「テスト」に一致します。ただし、括弧自体は含まれません。 |
[\))] | 終了の括弧を見つける。半角の ) または全角の ) のいずれかに一致する。 | 文字列「これは(テスト)です」や「これは(テスト)です」の中の「)`」または「)」に一致します。 |
この式はA1セルに含まれるテキストから、全ての括弧とその中のテキストを削除し、残りのテキストだけを返します。
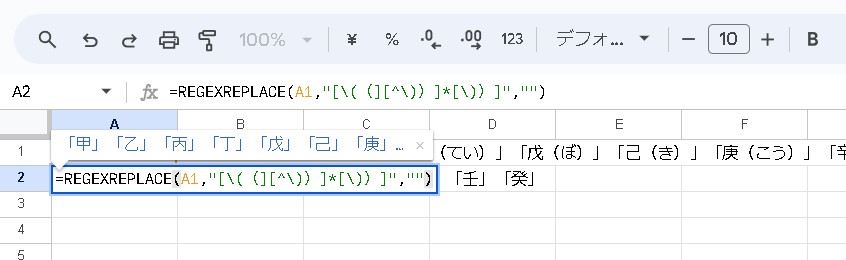

この式の結果は「甲」「乙」「丙」「丁」「戊」「己」「庚」「辛」「壬」「癸」となります。
まとめ
正規表現は非常に強力であり、複雑なパターンマッチングやテキスト処理のタスクを実行することができます。それぞれのパターンを理解し、適切に組み合わせることで、さまざまなテキスト処理のニーズに対応することが可能です。
このようにREGEXREPLACE関数を用いることで、特定のパターンにマッチする文字列を簡単に置換または削除することができます。
つづきは、また。