源内AIのOSS公開をきっかけに、「自分のPCにもAI環境を作りたい」と考える人が増えています。ただし、公式の源内AIをそのままローカルPCだけで完全再現するのは簡単ではありません。
そこで現実的なのが、OllamaとOpen WebUIを使って、ローカルPC上に「源内風のAI環境」を作る方法です。
この方法なら、OpenAI APIやClaude APIを使わず、ローカルPCだけでAIチャット環境を構築できます。
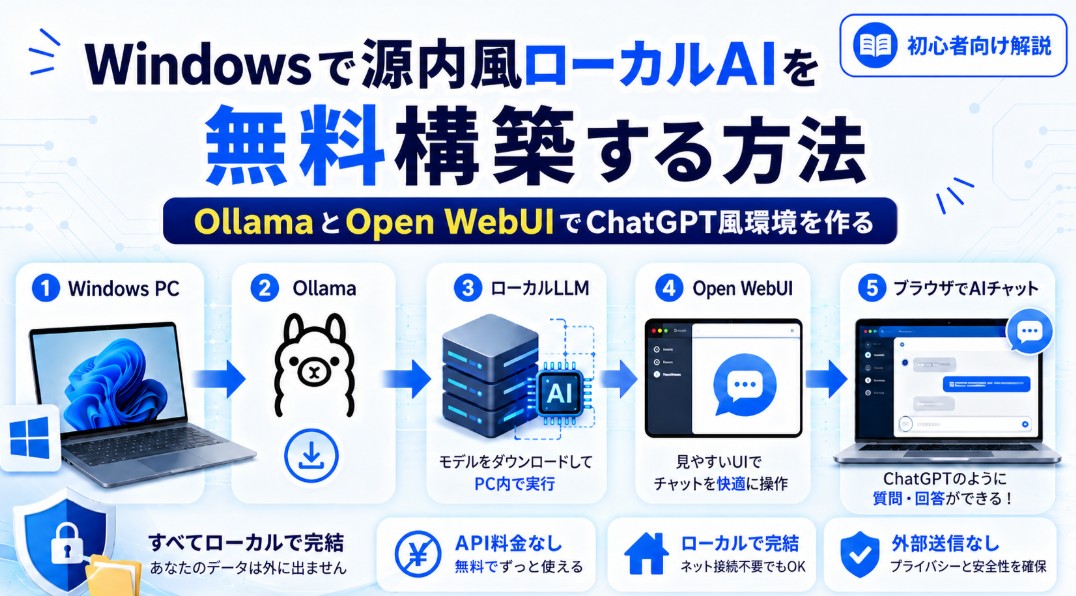
今回作る環境
今回作る構成は次のとおりです。
Windows PC
↓
Ollama
↓
ローカルLLM
↓
Open WebUI
↓
ブラウザで使えるAIチャット画面より安定して運用したい場合は、Dockerを使ってOpen WebUIを起動します。Open WebUIの公式ドキュメントでも、Dockerは多くのユーザーに推奨される導入方法として案内されています。
必要なもの
最低限、次の環境を用意します。
Windows 10 22H2以降、またはWindows 11
インターネット接続
十分な空きストレージ
できれば16GB以上のメモリ
Ollama
Open WebUI
Docker DesktopまたはDocker EngineOllamaのWindows版は、Windows 10 22H2以降を要件としています。NVIDIA GPUを使う場合は、NVIDIA 452.39以降のドライバーが必要です。
GPUがない場合でもCPUで動かせますが、回答速度は遅くなります。まずは軽量モデルで試すのが安全です。
手順1:Ollamaをインストールする
まずはOllamaをインストールします。Ollamaは、ローカルPCでAIモデルを動かすためのツールです。インストール後、コマンドからAIモデルを実行できます。
インストール後、PowerShellまたはターミナルを開き、次のコマンドでモデルを実行します。
ollama run gemma3Ollama公式ドキュメントでも、モデルの実行例としてollama run gemma3が案内されています。
初回実行時は、モデルのダウンロードが行われます。モデルサイズによっては時間がかかります。
手順2:軽量モデルで動作確認する
まずは軽いモデルでテストします。
ollama run gemma3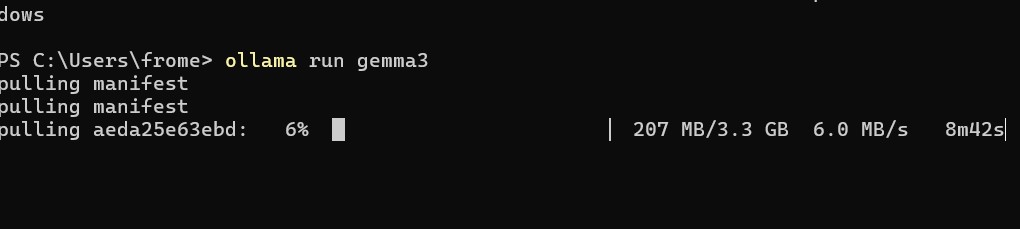
または、別の軽量モデルを使う場合は次のように実行します。
ollama run llama3.2起動後、ターミナル上で質問を入力します。
日本語で自己紹介文を作ってください。
返答が表示されれば、Ollamaは正常に動いています。
手順3:Open WebUIを導入する
OllamaだけでもAIは使えますが、ターミナル操作だけでは使いにくいです。
そこでOpen WebUIを使います。
Open WebUIを使うと、ブラウザ上でChatGPTのような画面を使えます。Open WebUI公式ドキュメントでは、Dockerで起動する場合、3000:8080でUIを公開し、http://localhost:3000にアクセスする手順が示されています。
手順4:DockerでOpen WebUIを起動する
Dockerが使える状態で、次のコマンドを実行します。
docker run -d -p 3000:8080 -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:main起動後、ブラウザで次を開きます。
http://localhost:3000初回アクセス時にアカウントを作成します。
手順5:Ollama内蔵版のOpen WebUIを使う方法
OllamaとOpen WebUIをまとめて動かしたい場合は、Ollama同梱版のOpen WebUIイメージを使う方法もあります。
GPUありの場合は次のコマンドです。
docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollamaCPUのみの場合は次のコマンドです。
docker run -d -p 3000:8080 -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollamaOpen WebUI公式ドキュメントでも、Open WebUIとOllamaを1つのコンテナでまとめて動かす構成が案内されています。
手順6:Docker Composeで管理する方法
毎回長いコマンドを打つのが面倒な場合は、Docker Composeで管理します。
作業用フォルダを作ります。
mkdir gennai-local
cd gennai-localdocker-compose.ymlを作成します。
services:
gennai-local:
image: ghcr.io/open-webui/open-webui:ollama
container_name: gennai-local
ports:
- "3000:8080"
volumes:
- ollama:/root/.ollama
- open-webui:/app/backend/data
restart: unless-stopped
volumes:
ollama:
open-webui:起動します。
docker compose up -dブラウザで開きます。
http://localhost:3000停止する場合は次のコマンドです。
docker compose down再起動する場合は次のコマンドです。
docker compose up -d手順7:モデルを追加する
Open WebUI上でモデルを選択できない場合は、Ollama側にモデルを追加します。
コンテナ名がgennai-localの場合は、次のコマンドでモデルを取得できます。
docker exec -it gennai-local ollama pull llama3.2取得後、Open WebUIを再読み込みし、モデル一覧に表示されるか確認します。
おすすめの初期モデル
最初は軽いモデルから試すのがおすすめです。
llama3.2
gemma3
qwen系の軽量モデル重いモデルをいきなり使うと、PCのメモリ不足や応答遅延が起きる可能性があります。
まずは「動くこと」を優先し、その後に精度の高いモデルへ変更する流れが安全です。
源内風に使うためのカスタム例
単にAIチャットを使うだけでは、源内風とは言えません。
業務用途に近づけるには、用途別のプロンプトを用意します。
たとえば、次のようなテンプレートです。
議事録要約用プロンプト
行政文書チェック用プロンプト
事業計画書作成用プロンプト
報告書作成用プロンプト
メール文面作成用プロンプト
FAQ回答用プロンプト
マニュアル検索用プロンプト源内の特徴は、単なる雑談AIではなく「業務特化のAIアプリケーション」を使う点にあります。公式の源内Webも、AIアプリ管理や外部マイクロサービスとして構築したAIアプリの追加・実行機能を持つ構成です。
ローカル環境でも、この考え方を取り入れることで、かなり実用的なAI基盤に近づけることができます。
ローカル文書を使ったRAG環境に発展させる
さらに実用性を高めるなら、ローカル文書を読み込ませて質問できる仕組みを作ります。
これがRAGです。
RAGとは、AIが単独で回答するのではなく、文書やデータベースを検索し、その内容をもとに回答する仕組みです。
源内AIアプリの公式リポジトリでも、AWS向けに行政実務用RAGの開発テンプレートが公開されています。
ローカル環境でRAGを使えば、次のような活用ができます。
PDFマニュアルを読み込ませて質問する
社内規程をもとに回答させる
議案書を要約させる
過去の議事録から論点を抽出する
FAQ文書をもとに回答させるただし、RAGは「文書を入れれば必ず正確に答える」仕組みではありません。文書の分割方法、検索精度、プロンプト設計、モデルの性能によって回答品質が変わります。
よくあるエラーと対処法
Open WebUIが開かない
まず、コンテナが起動しているか確認します。
docker psopen-webuiまたはgennai-localが表示されていなければ、起動できていません。
再起動します。
docker compose up -dポート3000が使えない
他のアプリが3000番ポートを使っている可能性があります。
その場合は、docker-compose.ymlのポートを変更します。
ports:
- "3001:8080"この場合、ブラウザでは次を開きます。
http://localhost:3001モデルが表示されない
Ollama側にモデルが入っていない可能性があります。
docker exec -it gennai-local ollama listモデルがなければ追加します。
docker exec -it gennai-local ollama pull llama3.2回答が遅い
回答が遅い場合は、モデルが重すぎる可能性があります。
対策は次のとおりです。
軽量モデルに変更する
同時に起動しているアプリを閉じる
メモリを増やす
GPU対応環境にする
小さい文書から試すローカルAIのメリット
ローカルAIのメリットは大きく3つあります。
API料金がかからない
外部サービスに文章を送信しない
自分の用途に合わせて自由にカスタムできる特に、業務文書、行政文書、社内資料、議案書、報告書などを扱う場合、外部AIサービスに内容を送らずに処理できる点は大きなメリットです。
ローカルAIのデメリット
一方で、デメリットもあります。
高性能モデルを動かすにはPC性能が必要
クラウドAIより回答精度が低い場合がある
初期設定に手間がかかる
自分で保守管理する必要がある
文書検索の精度調整が必要「無料で使える」というメリットだけを見るのではなく、運用管理の手間も含めて考える必要があります。
まとめ
源内AIを公式構成のままローカルPCだけで完全無料再現するのは簡単ではありません。
しかし、OllamaとOpen WebUIを使えば、源内AIの考え方を参考にした「源内風ローカルAI環境」は無料で構築できます。
最初に目指すべき構成は次のとおりです。
OllamaでローカルLLMを動かす
Open WebUIでChatGPT風の画面を作る
用途別プロンプトを登録する
ローカル文書を読み込ませる
業務用AIテンプレートを整備するこの流れで構築すれば、API料金をかけずに、社内や個人で使える実用的なAI環境を作ることができます。
公式の源内AIそのものを再現するのではなく、まずは「源内の考え方をローカル環境に取り入れる」ことが、無料で始めるための最も現実的な方法です。