
国立国会図書館(NDL)から、待望の軽量版OCRソフト NDLOCR-Lite が公開されました。 これまで高スペックなPC(GPU)が必要だった文字認識処理が、ついに一般的なノートパソコンでも手軽に実行できるようになります。
NDLOCR-Liteのここがすごい!
一般的なPCで動作(GPU不要)
これまでのNDLOCRは、動作に高性能なグラフィックボード(GPU)が必須でした。 しかし、今回のLite版はCPUのみで動作するため、家庭用のノートパソコンでもサクサク動きます。
マウス操作だけで完結
コマンド操作などは一切不要です。 専用のデスクトップアプリケーションが用意されており、普段使いのソフトと同じ感覚で、マウス操作だけで画像からテキストを抽出できます。
英文や手書き文字にも対応
従来のモデルが苦手としていた英文や、実験的ではありますが手書き文字の読み取りにも対応しました。
古い資料だけでなく、活用の幅が大きく広がっています。
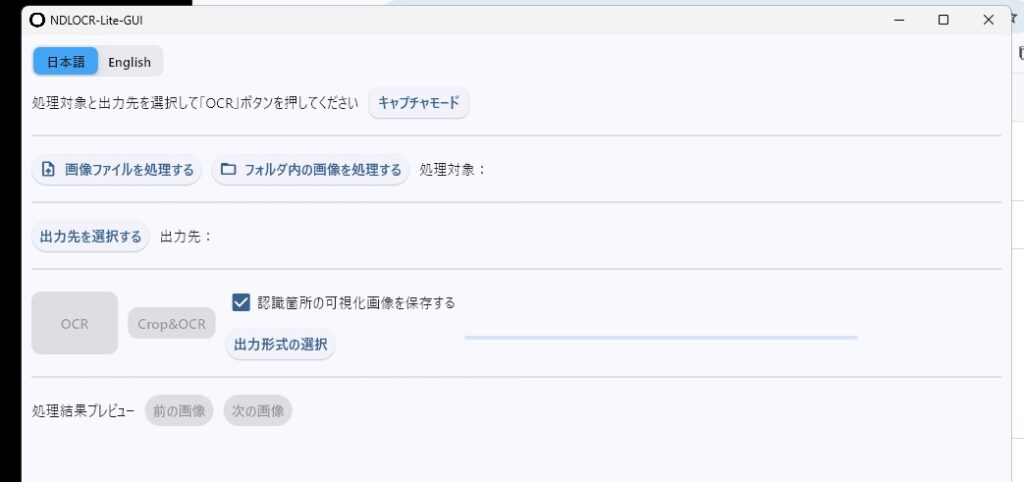
導入と使い方の流れ
- ダウンロード GitHubの配布ページから、Windows、Mac(macOS Sequoia対応)、Linuxの各OSに合わせた最新版をダウンロードします。 NDLOCR-Lite リリースページ
- アプリを起動 インストール後、デスクトップアプリを立ち上げます。
- 画像を読み込んで実行 テキスト化したい図書や雑誌の画像を選択し、実行ボタンを押すだけ。 数秒から数十秒で、画像内の文字がテキストとして出力されます。
利用時のポイント
- ライセンス CC BY 4.0ライセンスで公開されています。ルールを守れば、個人・商用問わず二次利用が可能です。
- 古典籍について くずし字や漢籍を本格的に読み込みたい場合は、別途公開されているNDL古典籍OCR-Liteを使用するのがベストです。
まとめ
専門知識がなくても、マウスひとつで古い資料や画像をテキスト化できる時代が来ました。 「画像の中に書いてある文字をデータ化したいけど、手入力は面倒……」 そんな悩みを持つすべての人にとって、最強のツールになりそうです。

NDLOCR-Liteの公開について | NDLラボ
NDLラボは、次世代の図書館システムの開発に資する要素技術の実証実験を行うためのウェブサイトです。NDLラボでは、国立国会図書館のサーバ環境や国立国会図書館が持つデジタル化資料のデータ・書誌データなどを研究者等に提供し、研究者等はその資源を...
lab.ndl.go.jp


