目次
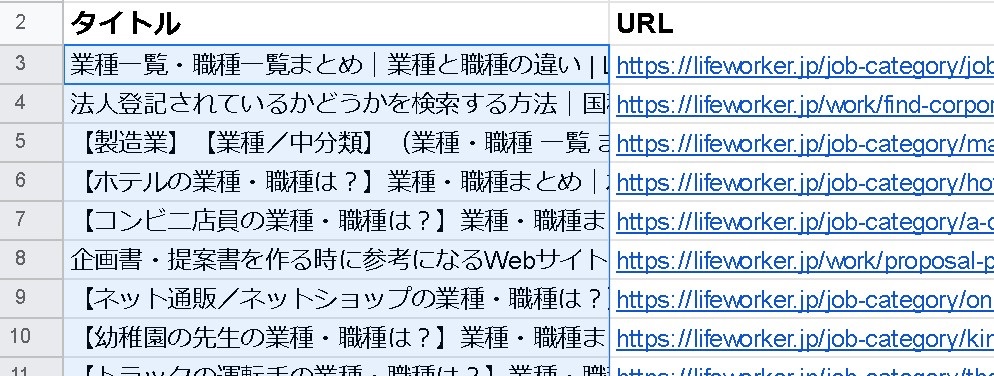
「URLの一覧からすべてのページタイトルを一気に取得したい」という、こんな時に使えるのがGoogleスプレッドシート独自の便利関数「IMPORTXML関数」です。
IMPORTXML関数とは?
=IMPORTXML(“URL”, “XPathクエリ”)
WEBサイトのページから、特定の条件( XPathクエリ )を使って、特定のデータを抽出することができる関数です。一般的には「スクレイピング」と呼ばれたります。※スクレイピングは禁止になっているサイトが多いので使用には注意しましょう。基本的には他の方のサイトで使うのはNGと思ってもらったほうが無難です。
XPathとは?
XPathとは「XML Path Language」の略で、マークアップ言語 XML に準拠した文書の特定の部分を指定する言語構文です。
HTMLは「html」→「body」→「h1」→…、とツリー構造になっていて、XPathは、スラッシュ “/” で区切りながら階層を記述し、基準となるノードから別のノードを指定してデータを抽出することができるといった特徴があります。
例: /html/body/div/div/…
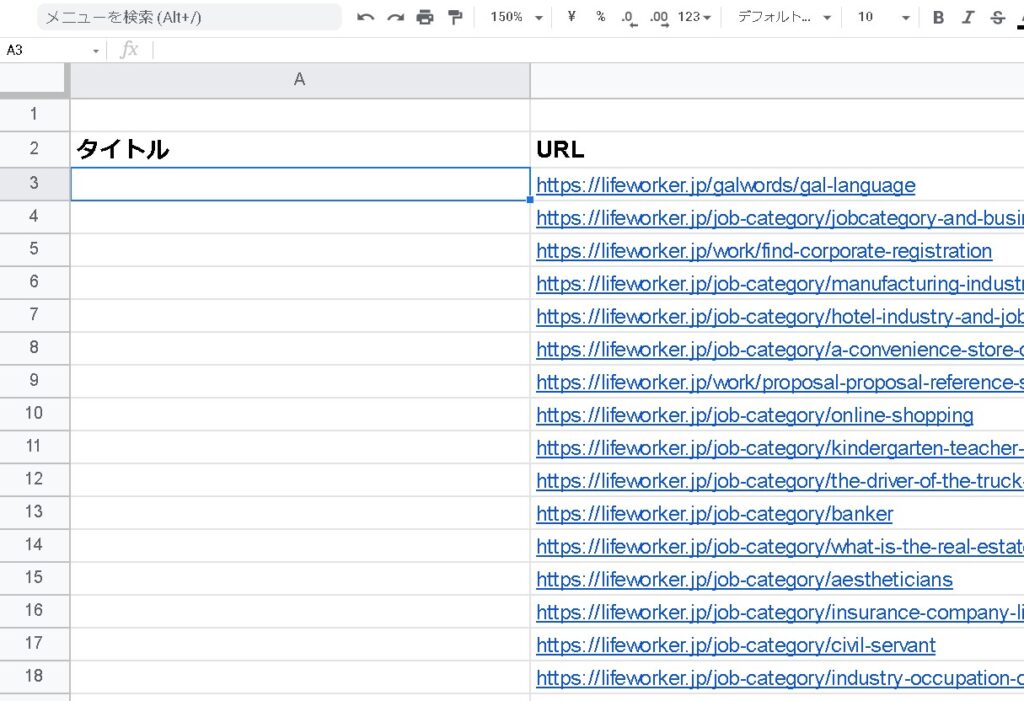
IMPORTXML関数の使い方
本題のIMPORTXML関数の使い方です。こちらはタイトルを抽出する場合の記述方法です。下記のように指定をします。
=IMPORTXML("http://example.com","//title")なんと、これだけでWEBページのタイトルを取得することができます。
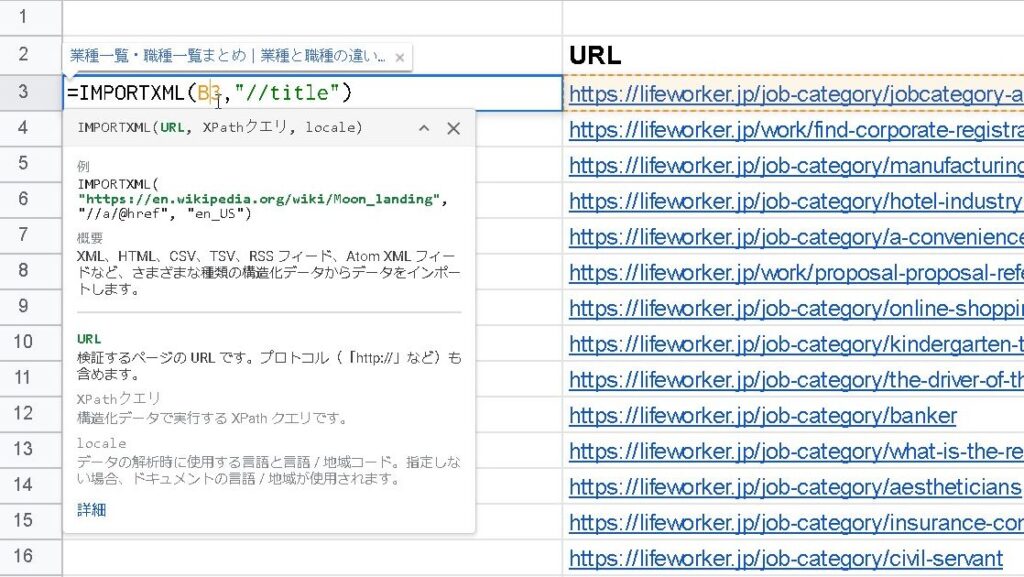
読み込みました!後は、一気に下までコピー貼り付け(またはオートフィル)すると、全てのページのタイトルが抽出できます。
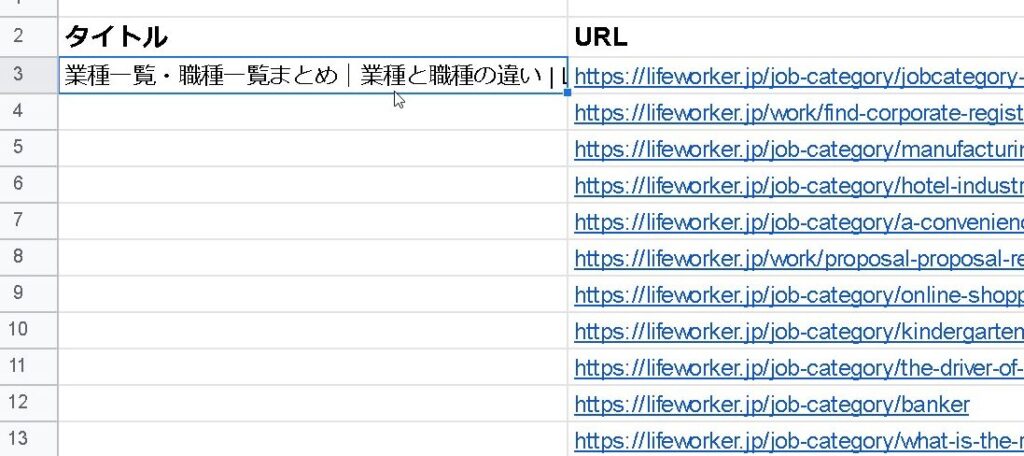
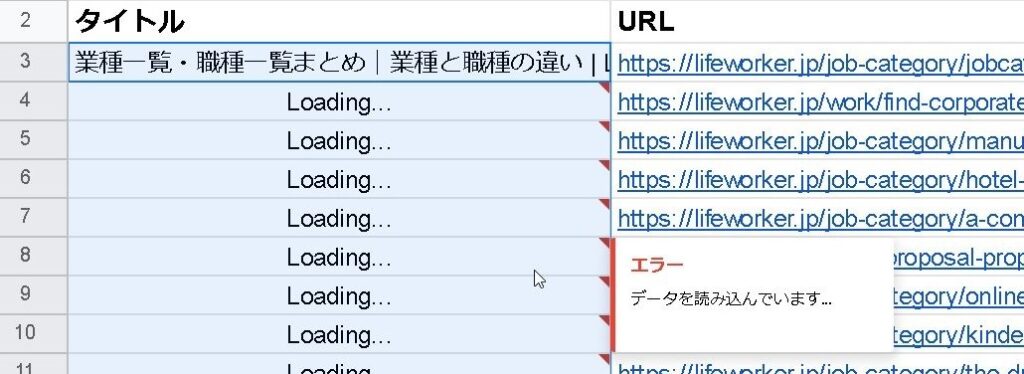
全部のページのタイトルが出てきました!
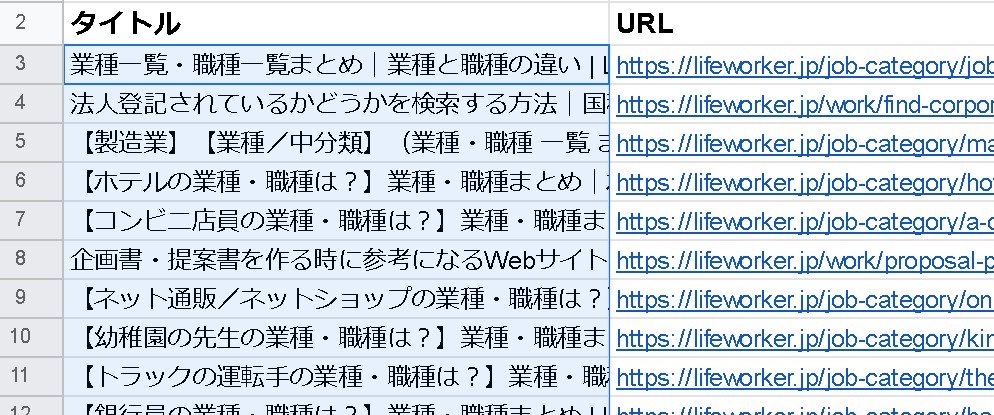
たったこれだけでWEBページのタイトルが取得できるとは、驚きです。
使用上の注意点・まとめ
注意点は、データ量が多すぎると表示が「Loading…」のままになって読み込まなくなりエラーになります。感覚では300件くらい以上になると厳しいかな?という感じです。読み込んだ後は、値の貼り付けなどを行って関数を消してあげた方が良さそうでうす。
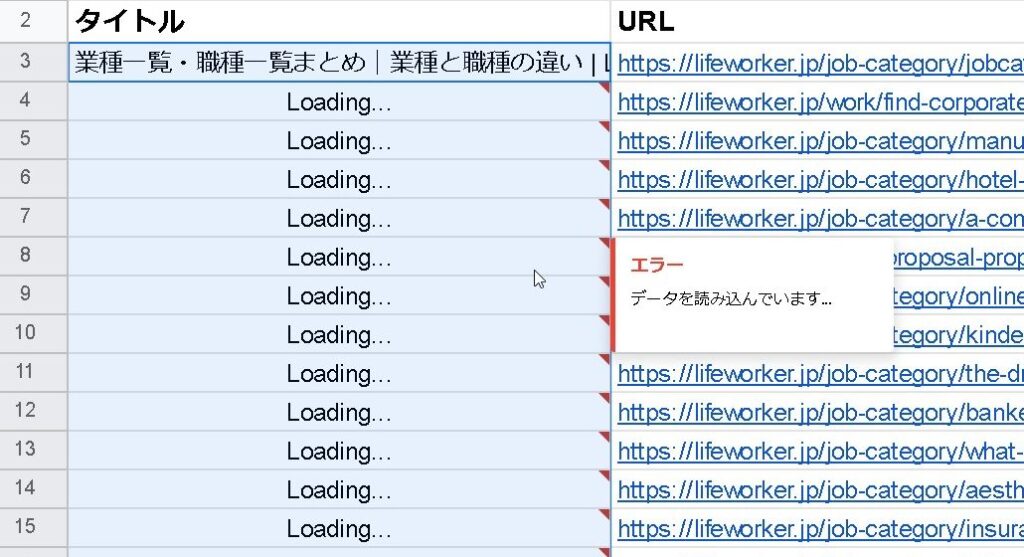
あと、スクレイピングは基本的に使用が禁止になっているサイトが多いので、使用にはくれぐれも注意しましょう。使い方を誤ると他のサイトさんにご迷惑が掛かる場合もあります。基本的には他の方のサイトで使うのはNGと思ってもらったほうが無難です。
URLの一覧があって、ここから1つずつタイトルを調べて貼り付け…などをしていると時間が掛かって仕方がありません。サイトマップなどからタイトルを抽出するときなどに役に立ちます。
ぜひ正しく便利にIMPORTXML関数を使いましょう!
御参考ください😃


